Парсинг новостей при помощи программы X-Parser
Итак, чтобы начать парсить новостные статьи, в программе X-Parser нам необходимо либо указать ключевые слова, либо указать ссылки на статьи, которые мы выбрали. В этой статье мы разберем как раз таки второй вариант, как правильно спарсить статьи используя ссылки.
Первое что нам нужно сделать, это найти подходящие статьи, которые мы хотим видеть у себя на сайте. Воспользуемся поисковой выдачей и найдем парочку таких статей. Теперь давайте скопируем ссылки и вставим в окно "Список кейвордов" в программе X-Parser. Для наглядности, посмотрите скриншот ниже:
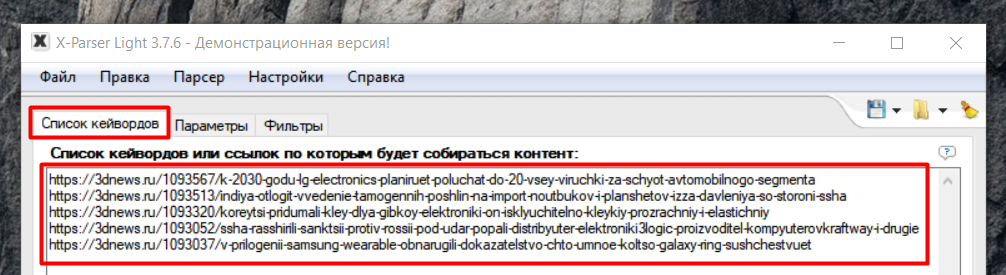
Отлично, ссылки есть, теперь самое время приступить к настройке программы. Для этого перейдем в окно "Параметры" и отметим необходимые пункты. В данной статье расписывать все основные функции программы X-Parser мы не будем, их слишком много и в этом нет необходимости. Чтобы ознакомиться с полным функционалом программы, Вы можете перейти по этой ссылке. А остановимся мы только на тех параметрах, которые нам необходимы при парсинге статей.
Настройка программы X-Parser для парсинга новостных статей у конкурентов
Итак, приступим к основной настройке перед запуском нашего парсинга. "Название парсера" здесь назовем наш проект "Новости", ведь именно новостные статьи мы будем добывать для нашего проекта. Далее, в графе "Сколько статей получить" можем оставить как есть "10". Далее переходим к такому пункту, как "Форматирование контента". Вот здесь остановимся более подробно. Для того, чтобы мы могли продолжить нашу дальнейшую работу в программе X-GPTWriter, нам необходимо получить результат в программе X-Parser в подходящем и корректном виде. Для этого мы можем выбрать такие значения:
- "Полное отсутствие разметки, текст как есть". Если разметка нам не важна и не нужна, выбираем данный вариант.
- "Сохранить базовую разметку". Если мы хотим получить статьи с разметкой, как на сайте у конкурента, можно остановиться на этом варианте.
- "Сохранить базовую разметку и изображения". Если хотим получить то же самое, что и в предыдущем пункте но с картинками, выберем данный вариант. Кстати, дополнительно можно выбрать вариант с загрузкой или без загрузки изображений. Тут Вы смотрите уже по ситуации и как Вам более предпочтительно.
- Сохранить базовую разметку, изображения и видео". Ну а этот вариант уже имеет на борту и картинки и даже видео. Также, если на странице конкурента имеются картинки и видео и Вы хотите видеть их и у себя, можете выбрать этот вариант.
Ну что же, с "Форматированием контента" мы разобрались. Для нашего примера мы выберем вариант "Сохранить базовую разметку".
Перейдем к следующему пункту нашей настройки "Алгоритм фильтрации статей". Здесь тоже остановимся более подробно и разберем две наиболее частые настройки: "Парсить непосредственно тексты статей" и "Парсить только явные статьи".
Напомню, что со всем функционалом программы Вы можете ознакомится прочитав вот здесь. Там очень детально разобрана каждая имеющаяся функция программы, так что переходите по этой ссылке. А мы вернемся к нашему параметру "Алгоритм фильтрации статей".
Итак, мы можем выбрать или "Парсить непосредственно тексты статей" или же "Парсить только явные статьи". При выборе первого параметра, спаршены будут абсолютно все статьи, ссылки на которые мы указали. Или же если будут указаны ключи вместо ссылок (отдельная статья), то же самое произойдет и в этом случае. Преимущество данного выбора в том, что на выходе мы получим большое количество статей, различных по качеству.
При выборе же второго варианта, статьи будут отбираться наиболее качественные. Это своего рода строгий фильтр, который отсеивает неподходящие статьи и выбирает только лучшие. Конечно, на выходе статей будет меньше, чем если бы мы выбрали вариант "Парсить непосредственно тексты статей", но в некоторых случаях это и требуется.
Ну что же, с предыдущими настройками мы разобрались, теперь перейдем к пункту "Формат обработанного текста". Здесь тоже давайте не особо задерживать, а выберем вариант "TXT - Текст как есть". Выбрав данный параметр мы получим на выходе текстовые файлы в формате .txt, которые нам как раз и понадобятся для дальнейшей работы в программе X-GPTWriter. Отлично, перейдем к следующему пункту.
"Формат сохранения контента". Мы практически завершили настройку программы, так что давайте быстро разберемся с данным параметром и пойдем дальше. Здесь мы выберем вариант "Каждая статья в отдельном файле в одной папке". Этот вариант к нашей задаче подходит идеально, так что мы выбираем именно его. Снова напомню читателям, что руководство по всем функциям программы доступно по вот этой ссылке. Там Вы сможете детально ознакомиться со всеми параметрами программы X-Parser.
И последняя надстройка, которую мы затроним будет "Путь к сохраненному контенту". Здесь мы можем оставить путь по-умолчанию, а можем выбрать свой. Давайте укажем свой путь к предварительно созданной папке "Новости". Отлично, Вы можете посмотреть на все настройки, которые мы затронули и произвели на скриншоте ниже. Отмечены именно те пункты, которые необходимы для нашей задачи - спарсить новостные статьи у конкурентов. Так что можете свободно ориентироваться на скриншот и выставить у себя те же параметры.
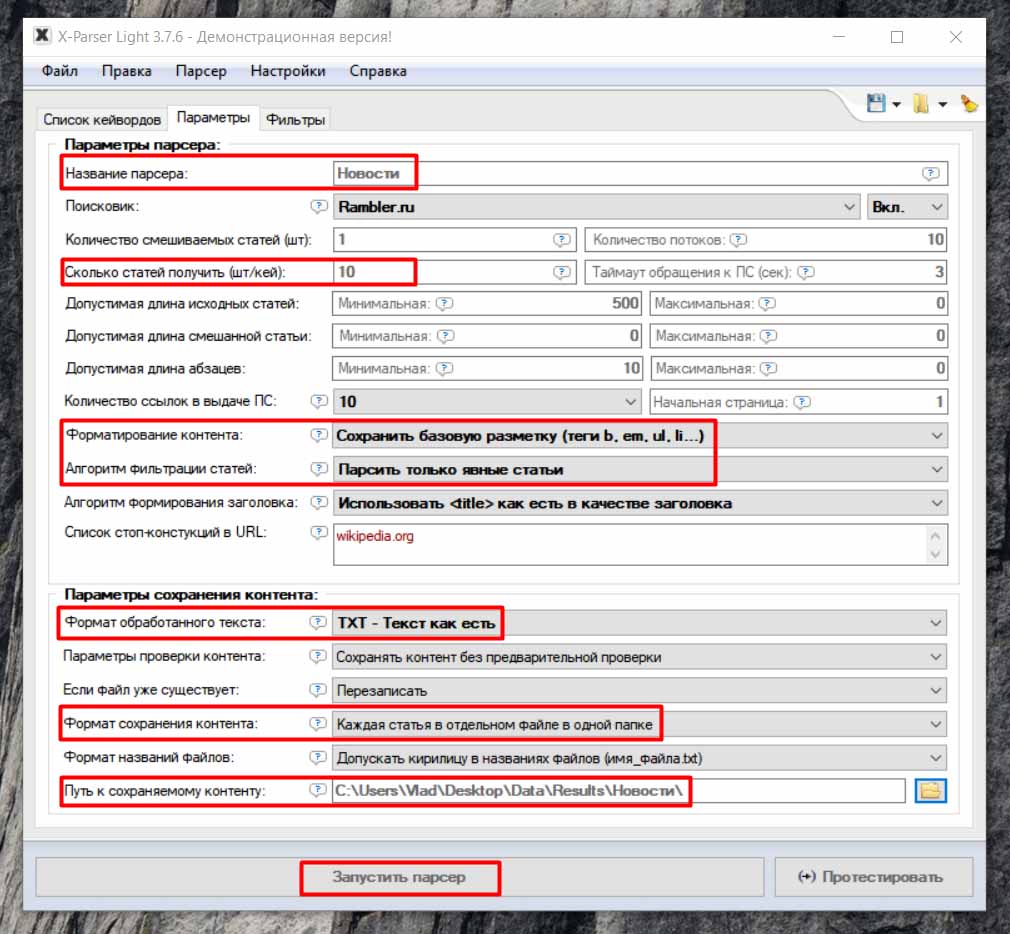 Отлично. Теперь можем запускать наш парсер. Жмем кнопку "Запустить парсер". Процесс пошел, нам осталось только дождаться его завершения. Ну вот, все готово, парсинг завершен и теперь мы можем ознакомиться с полученными результатами.
Отлично. Теперь можем запускать наш парсер. Жмем кнопку "Запустить парсер". Процесс пошел, нам осталось только дождаться его завершения. Ну вот, все готово, парсинг завершен и теперь мы можем ознакомиться с полученными результатами.
Давайте перейдем по указанному нами пути сохранения результата, а это напомню папка "Новости" и откроем один из находящихся там файлов. Как видите, все отлично спарсилось. Статьи получились с разметкой, как мы и указали в параметре "Сохранить базовую разметку". Смотрите скриншот ниже:
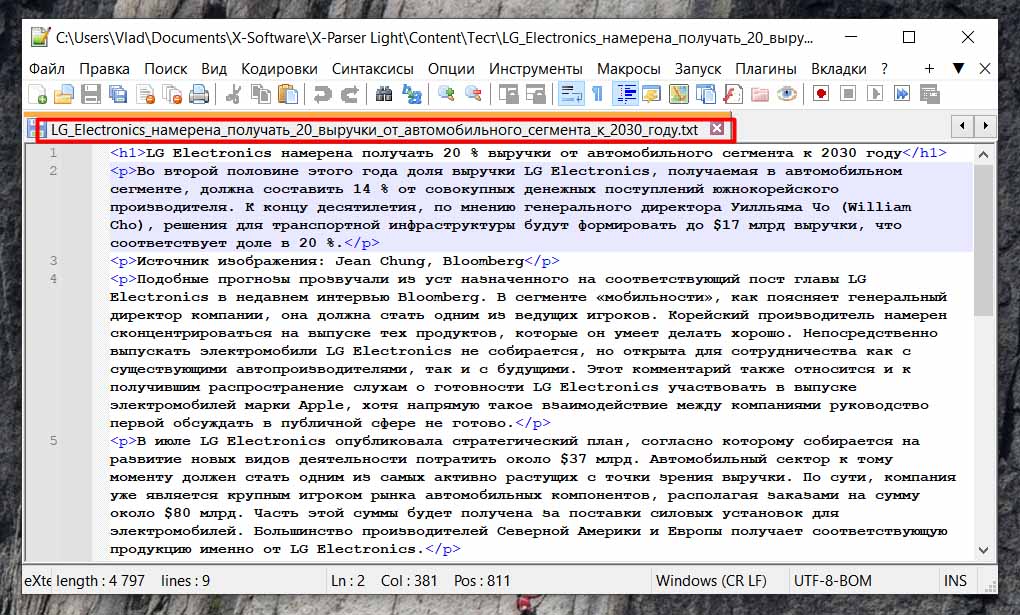
Ну что же, первый этап завершен, мы спарсили новостные статьи у наших конкурентов. У нас получилась целая папка статей в формате .txt и теперь самое время перейти ко второму этапу.
Теперь, если мы хотим униказизировать полученные новости, запускаем программу для генерации контента - X-GPTWriter и делаем все по плану, описанном в этой статье.
