А именно, мы можем, как и в Классическом рерайте, сделать рерайт основного текста, и помимо этого, мы также можем дописывать каждый раздел какими-то дополнительными данными.
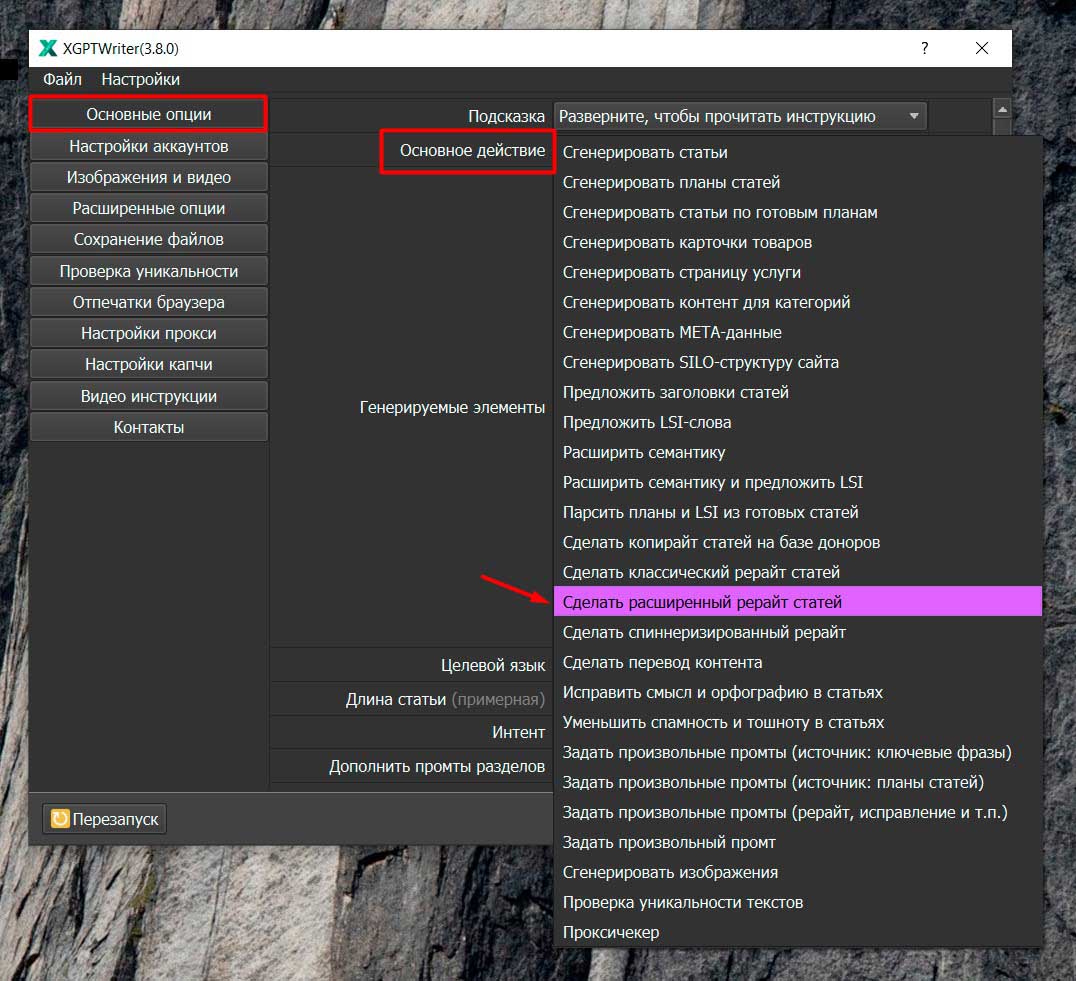
Например, у нас есть раздел от H1, до первого заголовка H2, например на один абзац. Когда мы включаем опцию Дописать каждый раздел (См. скриншот ниже), мы подаем команду дописать скажем еще 2 абзаца к этому разделу. Точно так же и для второго раздела, от первого заголовка H2 до второго заголовка H2, у нас также будет 2-3-4 абзаца, и мы к ним добавим еще несколько. И так для каждого раздела статьи.
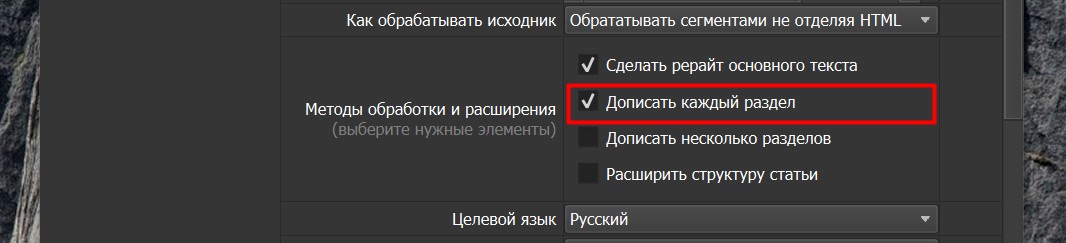
Если мы хотим дописывать не все разделы, а только несколько из них, например из четырех разделов мы хотим дописать первый и третий, то мы можем выбрать опцию Дописать несколько разделов (См. скриншот ниже). Соответственно опцию Дописать каждый раздел мы отключаем.
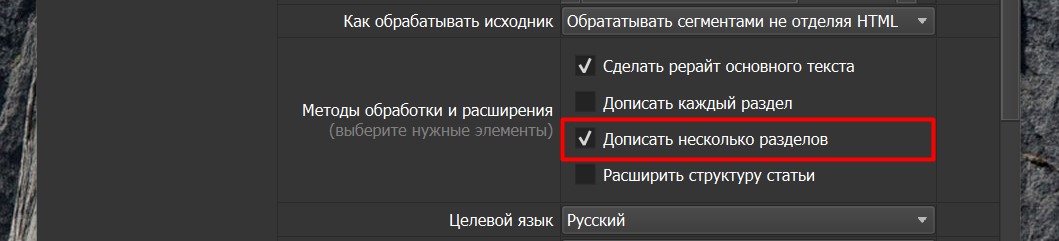
Если мы выбираем Расширить структуру статьи (См. скриншот ниже), то мы даем команду к нашим исходным четырем разделам дописать еще парочку разделов, для того, чтобы расширить контекст статьи. Таким образом, мы получаем на фоне нашей исходной статьи, статью, которая будет в полтора-два раза превышать по содержанию и наполнению исходную статью, что даст нам дополнительное преимущество при ранжировании, так как мы добавили дополнительную ценность исходной статье. По опытам, проведенным нами, данный режим на порядок лучше себя чувствует в выдаче чем Классический рерайт и даже Классическая генерация.
Также, очень важным отличительным свойством режима Расширенный рерайт является то, что мы фактически работаем с рерайтом как будто мы генерируем статью с нуля, но у нас исходники не ключевая фраза, а целая статья, и мы точно так же можем выбрать необходимые элементы, которые мы хотим сгенерировать, например, тайт, мета-описание, заголовок H1, H2, подзаголовки, тело статьи, вопрос-ответ добавить к статье, комментарии (См. скриншот ниже), но также, немаловажно то, что мы можем в нашу исходную статью добавить произвольные изображения спаршенные или сгенерированные. Для этого мы выбираем основное изображение, чтобы поставить заглавное изображение в статье, дополнительные изображения, чтобы раскидать изображения по телу статьи, и также мы можем нашей отрерайченной статье добавить видео с Ютуба по релевантной тематике статьи на основании ее заголовка.
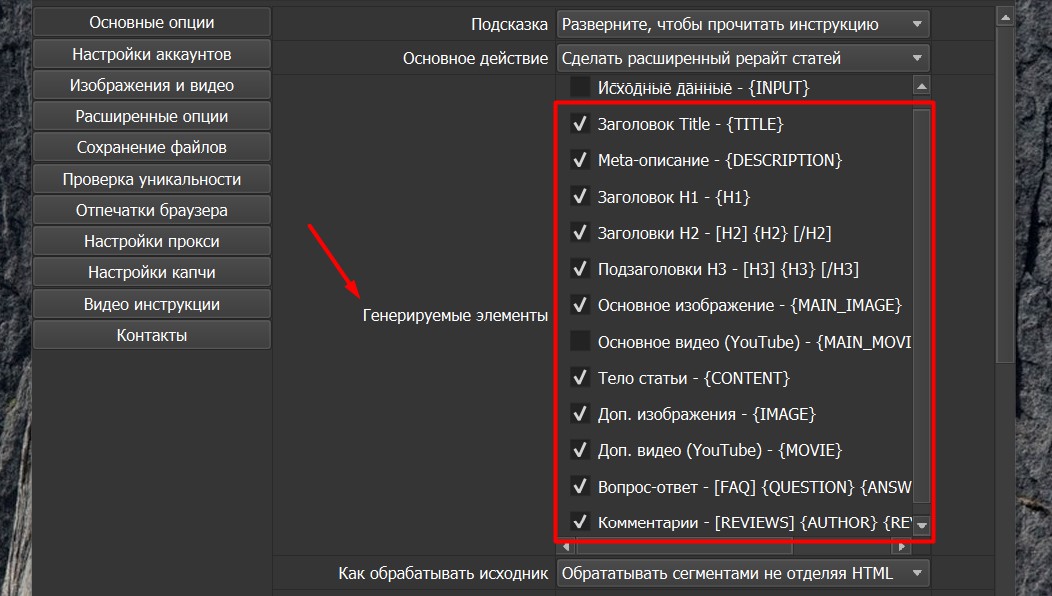
Как обрабатывать исходник (См. скриншот ниже). Здесь мы выбираем, Обрабатывать сегментами не отделяя HTML. То есть, мы берем заголовок и 3-4 абзаца и вставляем его в GPT прямо с разметкой и GPT его перерабатывает с тегами, что позволяет ему очень хорошо понимать контекст. Но он может, в очень редких случаях, немного сломать разметку и Вам нужно внимательно следить за тем, чтобы все было ОК, но в 95% случаев там все будет нормально. Если же при Ваших настройках например Вы используете АПИ Deepseek, Gemini или Произвольные АПИ или указываете другие GPT которые используют маленький объем данных на входе, например 1000 символов и у Вас категорически в данном режиме ломается разметка и ничего не помогает, то в этом случае Вы можете отделить текст от HTML, но тогда он будет обрабатываться построчно и HTML разметка гарантированно ломаться не будет. Данный режим Обрабатывать текст построчно, отделяя HTML категорически не рекомендуется использовать в Web режимах, потому что туда хорошо входит большой объем данных. Это актуально только для режима АПИ. Если в режиме АПИ у Вас ломается HTML разметка, только в этом случае переходим на данный режим.

Если мы хотим ограничить нашу статью по длине, то мы можем указать требуемую Длину статьи (См. скриншот ниже), таким образом, если при расширении структуры статьи или дописывании разделов, как только мы достигнем указанную длину, например в 15 000 символов, алгоритм поймет, что полученный объем достаточный и перестанет расширять структуру статьи и разделы и уложится в 15-17 тыс. символов.

Точно так же как при Генерации статьи мы можем Вставлять ссылки в текст из файла (См. скриншот ниже). Также мы можем выбирать любой формат на выходе.

Мы указывае исходные файлы (См. скриншот ниже) и формат файлов должен быть текстовые файлы или HTML файлы с HTML разметкой либо без нее, но если мы пишем в HTML формате или XML формате, то желательно чтобы HTML разметка в исходных статьях была.

Не изменять содержимое в тегах (См. скриншот ниже). Здесь мы можем указать, что мы не хотим рерайтить заголовки H1 и H2. А если мы не хотим рерайтить слова из заголовка H1, то мы указываем их в фигурных скобках. Тут мы не злоупотребялем количеством ограничений особенно фигурными скобками. Только один заголовок имеет смысл брать в скобки.

Пропускать первые строки (См. скриншот ниже). Данная опция позволяет добавить в начале файла несколько произвольных строк, которые мы хотим оставить в файле как есть. Соответственно, если у нас в первых трех строках есть какие-то пометки для какого-то нашего кастомного движка своего, и мы хотим начинать обработку с четвертой строки, то указываем что три строки мы хотим пропустить. Если у вас просто статья которая начинается с H1, то обязательно ставим 0.

Результатов на запрос. Здесь мы можем указать результатов на запрос, от 1 до бесконечности, но актуальнее делать 1. Не забываем настроить аккаунты. Также не забываем добавлять прокси в программу, если с Вашего IP наблюдаются проблемы с доступом к OpenAI, например если Вы находитесь в РФ, либо же Ваш IP находится просто в спамной подсети. Также можно включать ВПН. Но приоритетнее, если Вы используете многопоточный режим, использовать хотя бы один два, а лучше три прокси на поток.
Если у Вас возникает вопрос, как получить исходные статьи для рерайта, то Вам в этом плане поможет X-Parser. Мы открываем X-Parser, и задаем ключевые слова. Далее переходим во вкладку Настройки (См. скриншот ниже).
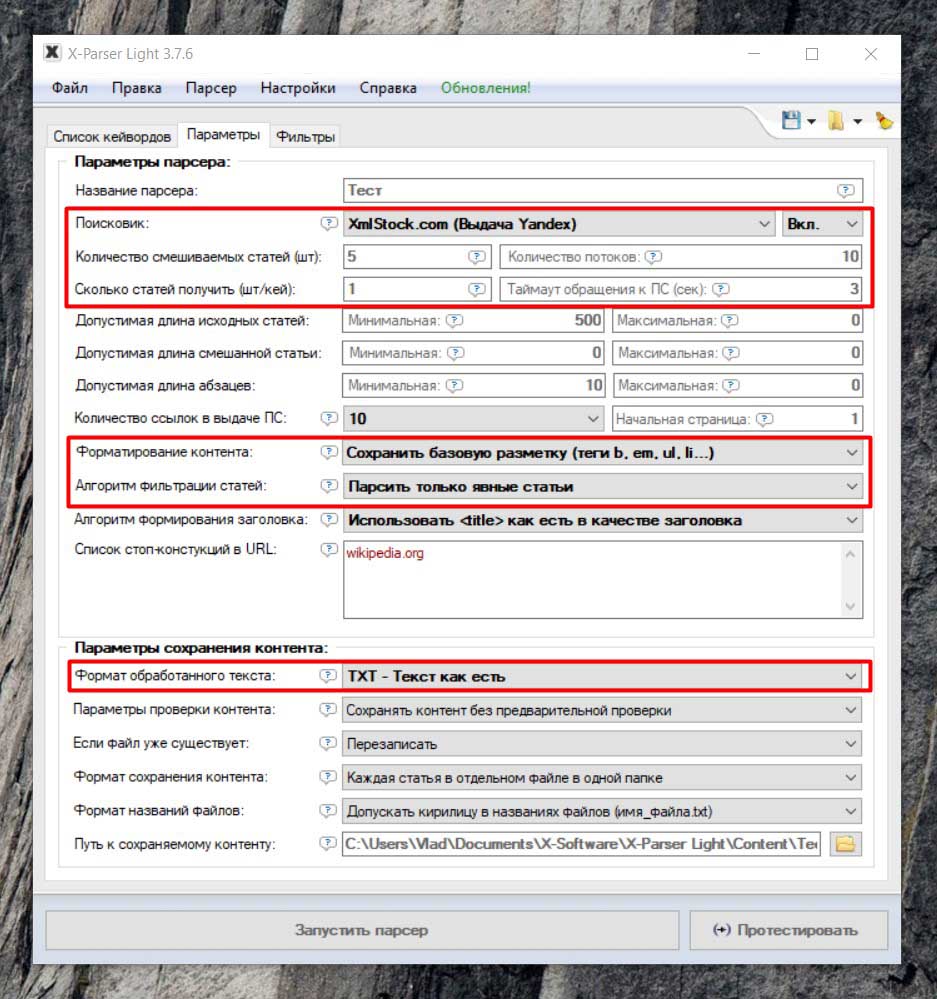
Выбираем поисковик. Лучше использовать какой-то XML сервис, чтобы не париться с капчей. При желании мы можем даже рерайтить не один источник, а смешать например 5 статей в одну при парсинге. То есть парсим пять статей, а на выходе получаем одну. Указываем Сохранить базовую разметку. Далее Непосредственно тексты статей либо Явные статьи. Если мы парсим по одному источнику на статью, то выбираем Текст как есть. Если хотим смешать части статей в одну статью, то выбираем Мешап по кейворду из текстов с разметкой.
Видео-инструкция:
