"Расширенные опции" делятся на открытые настройки и профессиональные, которые предусмотрены только для тех, кто очень хорошо разбирается в том, как работать с GPT на более продвинутом уровне. Профессиональные настройки скрыты для того, чтобы не усложнять жизнь обычным пользователям. Если же Вы хотите поиграть с такими настройками, то открываем их и смотрим, что здесь есть.
Первое что мы видим, это Алгоритм построения статьи (См. скриншот ниже). Здесь мы можем выбрать вариант “Учитывать тему статьи и заголовок раздела”. В этом режиме берется основной главный заголовок и в контексте него пишется раздел. Затем берется второй заголовок и главный заголовок и в контексте главного заголовка по заголовку второго раздела пишется раздел.
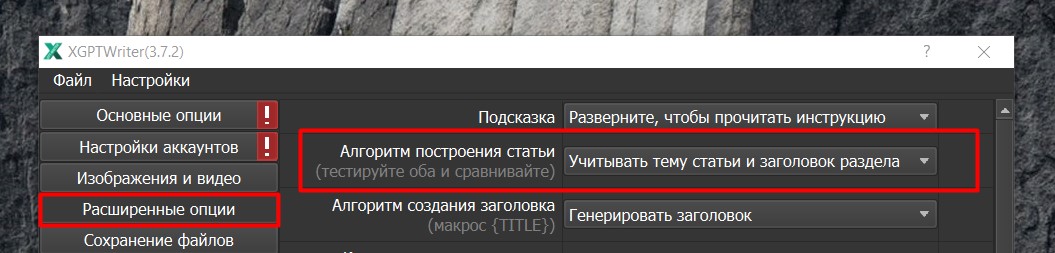
В режиме “Учитывать весь контекст повествования” учитываются сразу все заголовки, чтобы ChatGPT или другая нейросеть понимала в каком контексте нужно держаться, о чем уже было сказано, а о чем еще нет.
Алгоритм создания заголовка. Здесь все просто. Мы либо “Генерируем заголовок” на основе главной исходной ключевой фразы. Либо мы “Берем исходный кейворд” как есть. Берется то, что до первой точки с запятой. (См. скриншот ниже)

Как использовать заголовки. Здесь мы выбираем, как использовать заголовки: “Дословно” или “Перефразировать” ((См. скриншот ниже). Софт работает по следующему алгоритму. Сначала он генерирует план статьи и затем по этому плану генерирует статью. Либо же мы можем сами сначала сгенерировать план или задать ему готовый план. И данная опция как раз указывает, брать ли заголовки с поданного ему плана или из сгенерированного плана дословно или же перегенерировать их.

Далее идет опция “Контроль уровня спама в заголовках”. Если Вы генерировали много статей, то могли заметить, что в заголовках могут проскакивать повторения, особенно если контроль спама в заголовках отключен. То есть, в заголовках может повторяться например одно и то же словосочетание из исходного кейворда и очень часто. Для того, чтобы избежать спамности, мы выбираем пункт “Умеренно понизить спамность” (См. скриншот ниже). Параметр в меру понизит спамность, но без фанатизма. Если же мы видим, что нам этого недостаточно, то мы можем выбрать режим “Максимально понизить спамность”. Здесь необходимо понимать следующее. Если мы понижаем спамность умеренно, то мы позволяем GPT оставлять немного спама в заголовках, но никогда не терять смысл в заголовках. А если мы выбираем “Максимально понизить спамность”, то GPT, в попытке максимально избежать повторов, может немного потерять смысл и сгенерировать заголовки, которые будут немного выпадать из контекста.

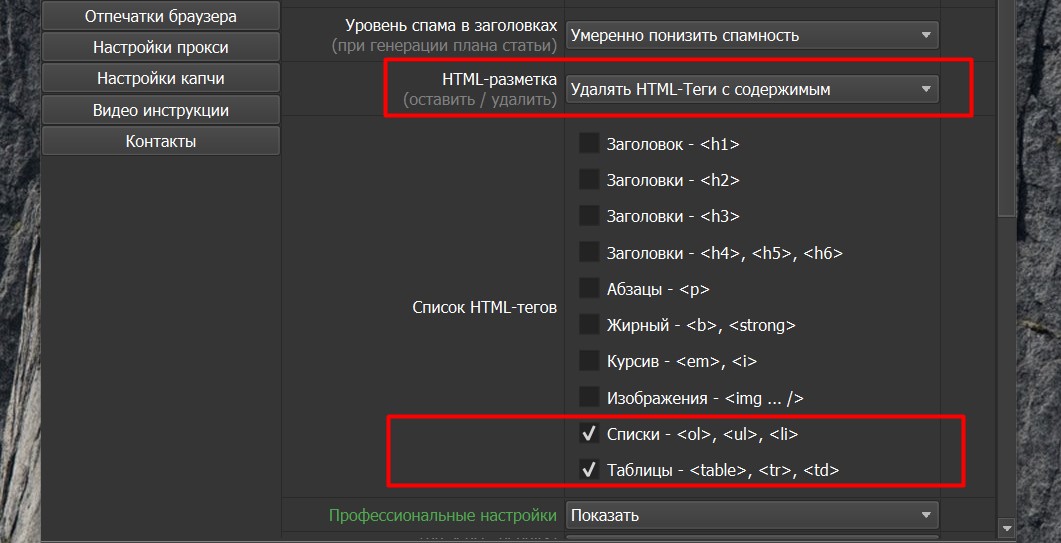
HTML-разметка. Здесь мы просто указываем, нужно ли нам использовать ее в готовых статьях или не нужно. Также мы можем указать конкретные теги, которые хотим, чтобы генерировались. Либо мы можем указать теги, которые хотим исключать. Мы даже можем удалять всё содержимое в указанных тегах при генерации. Например, в наших статьях нам не нужны таблицы и списки. Мы выбираем “Удалять HTML-теги с содержимым” и отмечаем таблицы и списки (См. скриншот ниже).
Профессиональные настройки в X-GPTWriter
Режим запуска: “Обычный” или “Ожидание контента”, то есть, режим API. Итак, Обычный режим (См. скриншот ниже). Генерируем статьи в обычном режиме, как мы это делаем всегда. А вот режим ожидания контента подразумевает следующее. Софт запускается в режиме опроса конкретной папки. Например Вы можете парсить статьи при помощи X-Parser, программа будет складывать их в эту папку, а X-GPTWriter будет их подхватывать и делать рерайт или копирайт этих статей. Данный режим сделан под связку с другим софтом.

Проверять правильность языка. Если Вы замечаете, что при генерации на каком либо иностранном языке проскакивают например абзацы или разделы на русском языке или на языке несоответствующем выбранному, то можно выбрать контроль языка. По-умолчанию он выбран, поэтому скорее всего Вы это не замечаете (См. скриншот ниже).

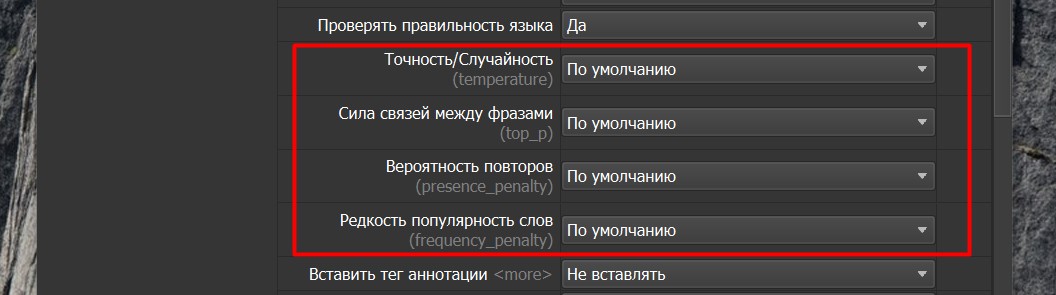
Далее идут параметры самого ChatGPT (См. скриншот ниже). Они работают только тогда, когда мы используем АПИ. В режимах веб версий эти параметры игнорируются.
“Точность/случайность (температура)”. Параметр, отвечающий за "консервативность" или "смелость" ответов GPT.
“Сила связей между фразами (Top-p)”. Параметр, который позволяет GPT отбирать следующее слово из вероятностного распределения наиболее вероятных слов.
“Вероятность повторов (Presence Penalty)”. Параметр контролирует, насколько модель предпочитает использовать слова и фразы, которые уже присутствуют в контексте.
“Редкость популярных слов (Frequency Penalty)”. Параметр, который используется для управления частотой повторяющихся фраз или фрагментов текста.
Данные настройки рассчитаны исключительно на профессионалов, которые имеют опыт тонкой настройки ChatGPT. Если Вы не знакомы с данными параметрами, то лучше всего их оставить по умолчанию.
Вставить тег аннотации (См. скриншот ниже). Данный параметр позволяет вставлять тег для сайтов на Wordpress. Можно выбрать “Вставлять после первого абзаца”, “После второго”, либо “После первого раздела”. Если Ваш шаблон требует разделение контента тегом , то Вы можете использовать данную настройку. В противном случае, этот параметр Вам не нужен.

Если выбрана генераци FAQ, то мы можем указать, сколько нам необходимо сгенерировать вопросов-ответов. Мы можем выбрать предлагаемый в программе диапазон или же задать свой. То же самое касается комментариев. Если мы их генерируем, то в данной опции мы также можем выбрать необходимый диапазон, сколько комментариев нам нужно. Или же указывать свои значения. (См. скриншот ниже)

Тип имен для отзывов. Опять же, если мы генерируем отзывы, то мы можем указать, использовать ли имена и никнеймы или имена с фамилиями. Или же выбрать вариант Вперемешку. (См. скриншот ниже)

Далее идут два очень полезных параметра, которые отвечают за фильтрацию ненужного нам контента. И первый такой параметр это “Фильтр первого абзаца секции” (См. скриншот ниже). Данный параметр применяется к первому абзацу каждой секции со второй по последнюю. Фильтр срезает первый абзац в каждой секции. Второй параметр “Фильтр абзацев” применяется для всех абзацев кроме первого в секции. Данный фильтр позволяет срезать выводы, заключения и так далее.

Далее идет очень полезная опция, которая позволяет софту оповещать Вас в Телеграмме о том, что задание выполнено. Итак, в пункте “Оповещение в Телеграм” выбираем “Отсылать”. Затем копируем ссылку из пункта “Подключение бота” и открываем ее в браузере или в Телеграме. Нажимаем Start. Далее копируем вторую ссылку из поля “Получить свой ID”. Также открываем ее в браузере или в Телеграмме. Запускаем бот и копируем числовое значение из строки Your user ID. Вставляем полученный код в программу. Отлично, таким образом мы подключили бота к программе (См. скриншот ниже). Теперь при запуске генерации, бот будет информировать нас о статусе работы программы.
Сохранение файлов в X-GPTWriter
Когда мы включаем Профессиональные настройки, то в левой панели программы у нас появляется вкладка “Сохранение файлов” (См. скриншот ниже). Давайте рассмотрим, что мы можем здесь настраивать.
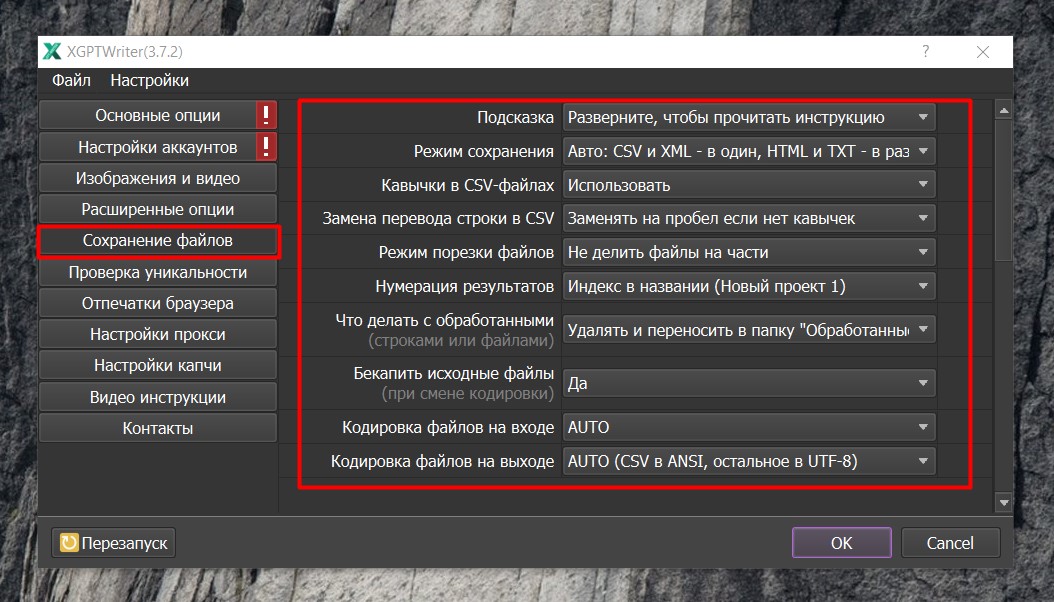
Вцелом, данные настройки настроены оптимально и не требуют никакой коррекции. Но если Вы очень сильно хотите с ними поиграться, то давайте попробуем. Первое, что мы здесь видим, это “Режим сохранения”. По-умолчанию, здесь установлен режим “Авто”. В этом режиме у нас файлы CSV и XML сохраняются в один файл. Если мы выбираем шаблон в пункте “Формат на выходе” CSV или XML, то результаты будут сохраняться в один файл автоматически.
Если же мы выбираем HTML или TXT, то результаты у нас автоматически сохраняются в разные файлы. Если нам необходимо всегда всё сохранять в один файл, то мы выбираем “Всё в одном файле”. Если нам необходимо всегда раскидывать наши статьи по файлам в одной папке, то выбираем “В разных файлах в одной папке”. Если же мы используем “Тип исходных данных” “Список файлов (папка)”, то мы можем группировать наши результаты по названию исходного файла. Для этого выбираем опцию “В разных файлах с группировкой по исходникам”. Оптимальным же выбором является режим “Авто”. (См. скриншот ниже)

Далее идут настройки CSV файлов (См. скриншот ниже). Это профессиональные настройки для тех, кто работает с CSV файлами. Если Вы обнаруживаете, что при работе CSV файл собирается некорректно и Вам мешают кавычки внутри текста, которые сбивают форматирование ячейки, то Вы соответственно можете выбрать “Использовать кавычки” или “Удалять”. Если Вы обнаруживаете, что Вам мешают переводы строк, то с помощью этой опции Вы можете откорректировать использование перевода строки.

Режим порезки файлов (См. скриншот ниже) для нас актуален, если мы используем в качестве результирующего формата “XML - текст в формате WordpressXML”, то есть, хотим импортировать статьи в Wordpress. Часто бывает так, что при импорте Wordpress не пропускает файлы с большим количеством статей. Если вдруг, мы столкнулись с этой проблемой, то мы можем порезать результирующий файл по 100, 500 или 1000 результатов или же мы можем указать свое конкретное значение.

Нумерация результатов. Если мы генерируем сразу по несколько результатов на каждый запрос, например по пять, то нужно иметь в виду, что мы будем получать пять комплектов статей. Программа создаст папку Новый проект или папку с любым другим названием, которое мы укажем, и будет добавлять единичку к названию папки, например, Новый проект 1, Новый проект 2 и так далее. В результате мы получим пять папок с пятью комплектами статей для пяти сайтов. В данной же опции (См. скриншот ниже) мы можем указать программе создавать папки в директории, где сохраняются наши результаты. Или же создавать папку и уже в ней формировать подпапки.

Что делать с обработанными. Далее у нас идет очень полезная опция, которая позволяет резервировать обработанные исходные данные будь это ключи или статьи. Итак, мы можем выбрать вариант “Оставлять как есть”. В этом случае исходные данные остаются в исходном файле и никуда не деваются. Если мы вдруг остановили процесс генерации на пятидесятом ключе, то при перезапуске программы генерация начнется с первого ключа. Если мы выбираем вариант “Удалять файлы или строки”, то они безвозвратно удаляются из файла. То есть, написали по кейворду статью - удалили. И оптимальный режим “Удалять и переносить в папку Обработанные” (См. скриншот ниже). Таким образом, те кейворды и статьи, которые были обработаны перемещаются в папку “Обработанные”. Мы можем в любой момент остановить процесс генерации и затем продолжить с того места, на котором остановились. А если вдруг, мы где-то что-то напутали, мы всегда можем из папки Обработанные вернуть наши кейворды обратно.

Следующие три опции касаются исходной кодировки и кодировки файлов на выходе (См. скриншот ниже). Здесь по-умолчанию стоит режим АВТО, который очень хорошо отрабатывает. Но если вдруг, Вам потребуется указывать кодировку явно и Вы выбираете кодировку отличную от UTF 8, например у Вас файлы в ANSI, то рекомендуется бэкапить исходные файлы, на случай, если вдруг произойдет какая либо непредвиденная ситуация при смене кодировки исходного файла.
Кодировка на выходе. Если мы хотим, чтобы наши результаты сохранялись в конкретной кодировке из предложенных, то мы выбираем необходимую нам опцию и получаем нужную нам кодировку. По умолчанию, установлен режим “AUTO”. Таким образом, CSV у нас идет в ANSI, чтобы файлы корректно открывались в Excel. А все остальные файлы по умолчанию сохраняются в UTF 8. Если Вы хотите все файлы сохранять в ANSI, то выбираем вариант ANSI. Если хотим UTF c BOM, выбираем его. Но оптимально оставлять эту опцию в режиме AUTO.

Отпечатки браузера в X-GPTWriter
Также мы можем заметить, что при включении “Профессиональных настроек” в боковой панели программы у нас появилась вкладка “Отпечатки браузера” (См. скриншот ниже). Отпечатки браузера актуальны только если мы используем режимы работы через веб-интерфейс. Соответственно, они помогают нам эмулировать множество пользователей и сокращать количество банов от CloudFlare или от OpenAI. По-умолчанию, софт работает с дефолтными отпечатками и в принципе этого достаточно. Но если Вы знакомы с сервисом Fingerprint Switcher и у Вас есть аккаунт, то использование данного сервиса тоже Вам доступно.
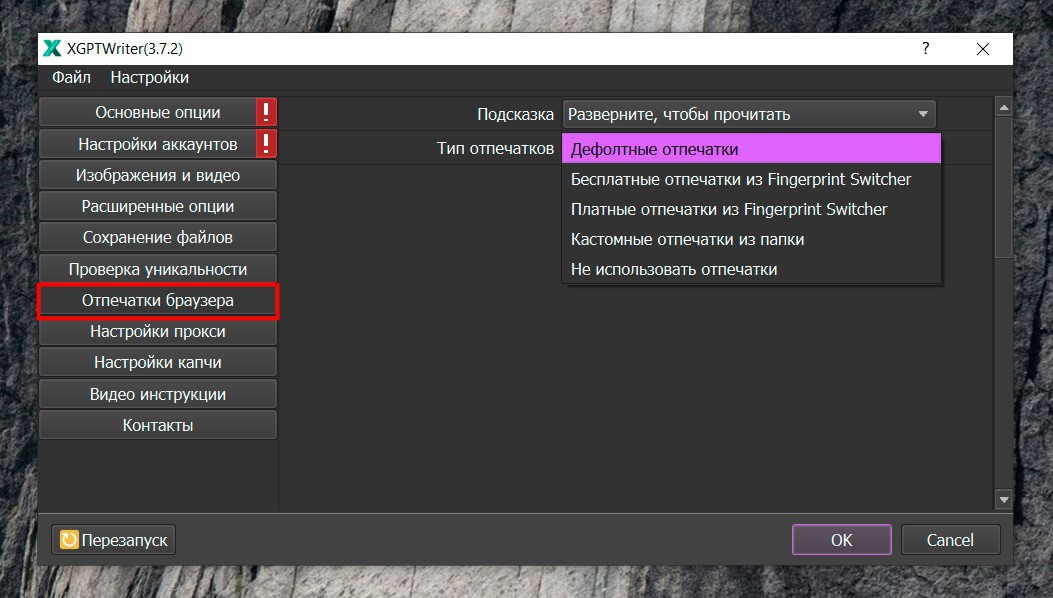
Как видите, Вы можете использовать как бесплатные отпечатки из Fingerprint Switcher, так и платные. Если Вы решите использовать бесплатные отпечатки, то имейте ввиду, что Вам будут доступны единовременно только два отпечатка в минуту и если Вы решите использовать больше одного двух потоков, то скорее всего поймаете блокировку от Fingerprint Switcher из-за того, что упретесь в лимит. Поэтому бесплатные отпечатки актуально использовать только для теста.
Далее Вы может использовать платные отпечатки уже полноценно. Для этого Вы покупаете ключ в Fingerprint Switcher. Переходим по данной ссылке (См. скриншот ниже), нажмем получить ключ и покупаем на один или на три месяца. Проходим регистрацию и получаем ключ. Вставляем его в поле (См. скриншот ниже). Мы можем указать, насколько свежие отпечатки нам нужны и соответственно, мы будем получать их в режиме реального времени.
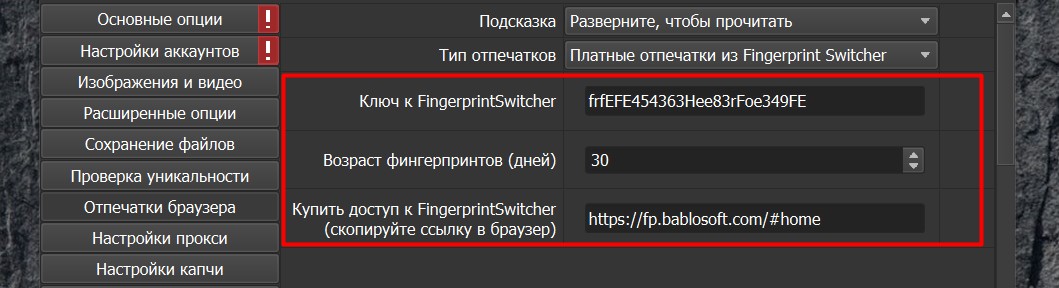
Также, если у нас есть совместимые с БАС отпечатки, мы можем указать папку с такими отпечатками. Либо же мы можем просто отключить отпечатки, но делать этого не рекомендуется. Лучше использовать дефолтные отпечатки или платные с Fingerprint Switcher.
Видео-инструкция:
