Итак, при помощи программы мы можем генерировать статьи с картинками и видео. Программа сгенерирует или спарсит картинки с видео исходя из Ваших исходных данных и вставит их в статьи.
Для того, чтобы у наших статей была заглавная картинка, мы отмечаем пункт “Основное изображение”. Если мы хотим, чтобы в статьях, помимо заглавной картинки, в тексте были еще и другие изображения, отмечаем пункт “Дополнительные изображения”. См. скриншот ниже. Их количество мы установим позже.
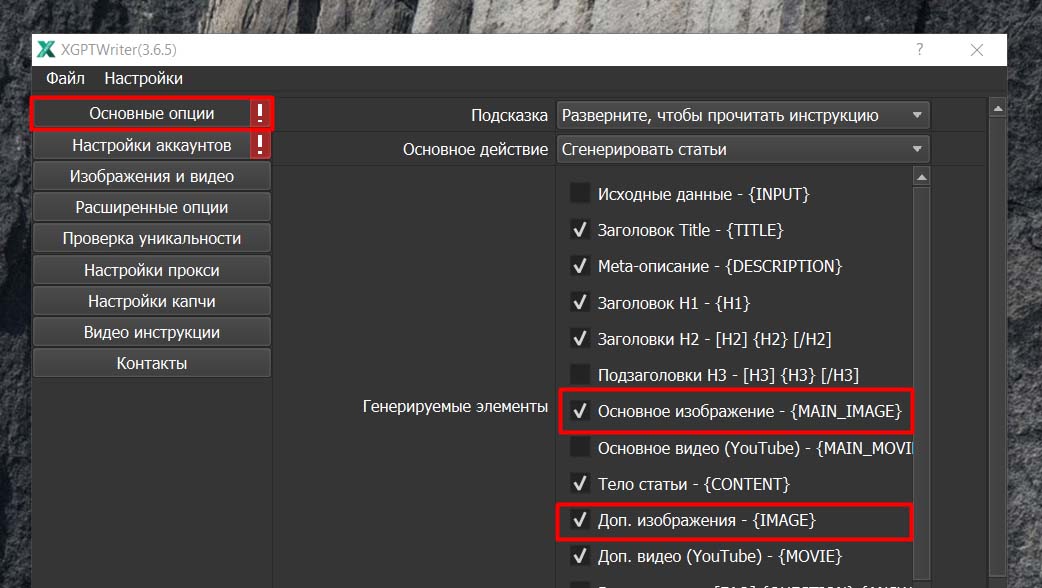
Если нам нужно, чтобы в качестве заглавной картинки было видео, вместо “Основного изображения” отмечаем пункт “Основное видео”. См. скриншот ниже.

Если хотим, чтобы в конце статьи вставлялись видео, отмечаем пункт “Дополнительное видео”. См. скриншот ниже. Их количество мы также установим позже.

Теперь давайте перейдем в раздел “Изображения и видео” и посмотрим, чем мы можем сгенерировать или откуда спарсить изображения. См. скриншот ниже.
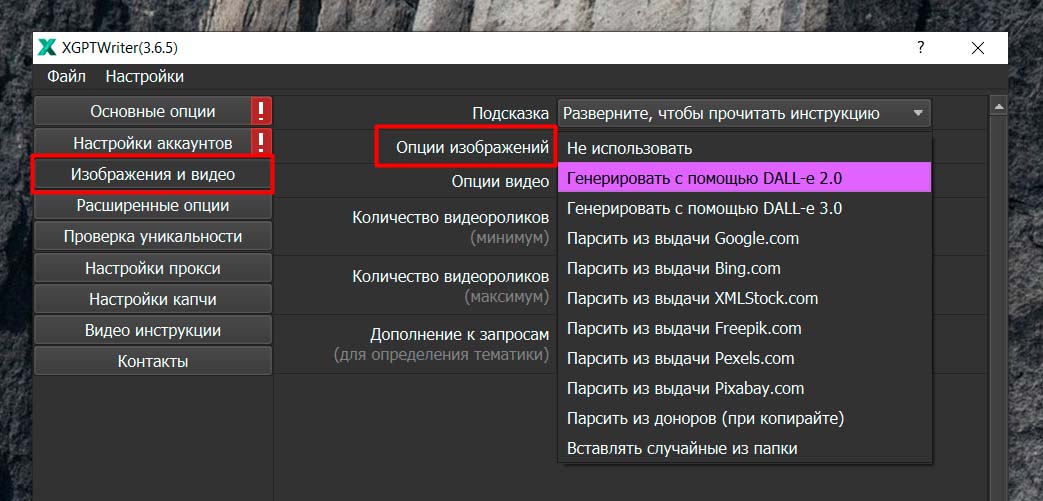
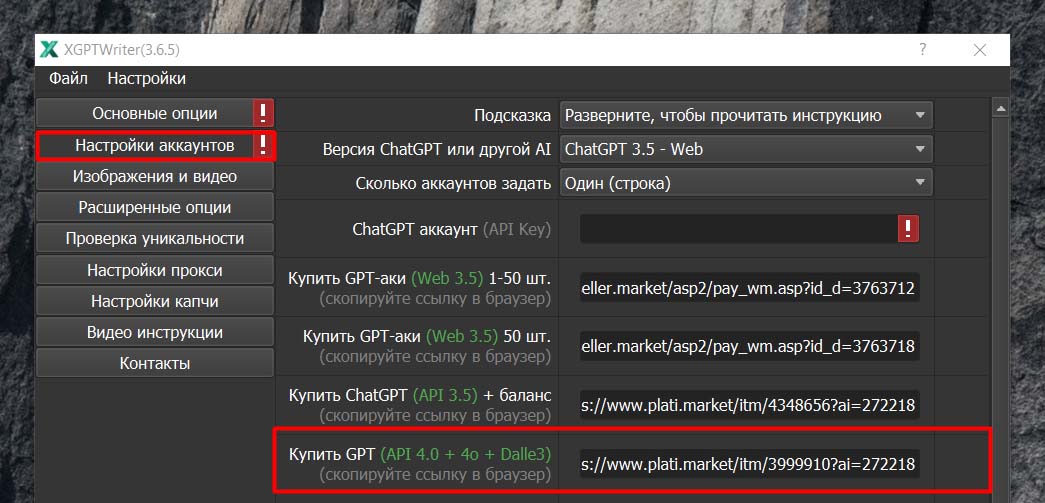
Итак, сгенерировать картинки мы можем при помощи режимов Dall-e 2 и Dall-e 3 от компании OpenAI. Для этого нам понадобится аккаунт ChatGPT с АПИ, который можно купить в интерфейсе программы (См. скриншот ниже.) или же самостоятельно зарегистрировав аккаунт на сайте OpenAI и пополнив баланс.
Также мы можем парсить картинки из поисковой выдачи Google и Bing. См. скриншот ниже. Программа будет брать картинки с сайтов исходя из наших ключевых слов и вставлять их в тексты статей.

Если мы планируем генерировать много статей с картинками и использовать для этого парсинг из поисковиков, то рано или поздно, мы столкнемся с капчей. Поэтому, если мы хотим генерировать большие объемы статей с изображениями, выбираем режим “XMLStock.com”. Никаких блокировок IP, капч и тому подобного. Только высокая скорость парсинга картинок и очень демократичная цена.

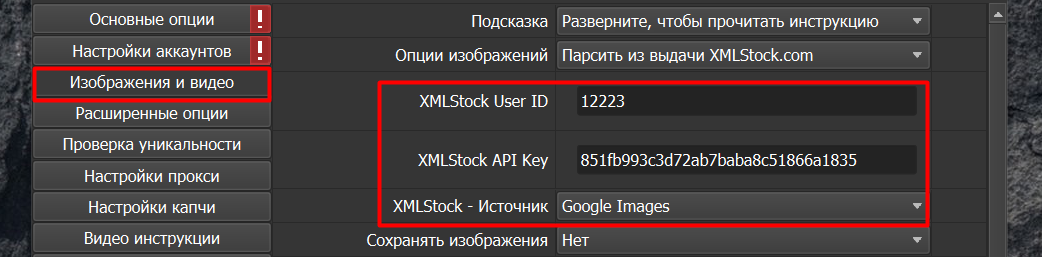
Регистрируемся на сайте XMLStock.com. Подтверждаем почту и входим в личный кабинет. Копируем значения User и Key. См. скриншот ниже.

Далее вставляем данные значения в программу в соответствующие поля (См. скриншот ниже.) Затем в поле “XMLStock - Источник” выбираем, откуда хотим парсить картинки: из Гугла или Яндекса.
Также мы можем парсить картинки из бесплатных фотостоков: Freepik, Pexels и Pixabay. См. скриншот ниже. Во всех трех вариантах, программа будет парсить картинки без наличия авторских прав и не подпадающих под действие лицензии Creative Commons. Таким образом, права авторов на изображения нарушаться не будут.

Далее у нас идет режим “Парсить изображения из доноров”. Данный режим можно использовать только если в качестве основного действия будет выбрано “Сделать копирайт статей на базе доноров”. См. скриншот ниже.
Суть режима заключается в том, что мы предварительно при помощи программы X-Parser парсим сайты и статьи наших конкурентов вместе с картинками. Далее подаем программе спаршенные данные и получаем абсолютно уникальные статьи с картинки как у наших доноров.
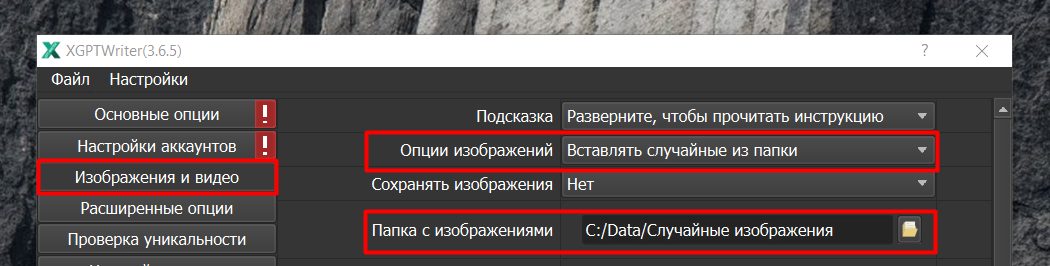
Последний режим - “Вставлять случайные из папки”. Задаем папку с картинками из которых программа будет выбирать случайные изображения и вставлять их в тексты наших статей. См. скриншот ниже.
Теперь пройдемся по дополнительным настройкам. “Сохранять изображения”. Можем выбрать варианты “Да”, “Нет”, и сохранять в режиме “Base64”. См. скриншот ниже. При выборе последнего, картинки будут вставляться в текст статьи в виде кода.

“Путь к картинкам в документе”. При генерации статей с картинками, в выбранной локации для сохранения результатов программа создаст папку wp-content, а в ней папку images. В этой папке и будут сохраняться сгенерированные или спаршенные изображения. См. скриншот ниже.

Затем, чтобы картинки корректно отображались на сайте, необходимо перенести данную папку wp-content в директорию нашего сайта.
Далее, мы можем задать максимальную и минимальную ширину изображений в пикселях для генерации или парсинга. Картинки будут генерироваться или парситься исходя из указанных значений максимальной и минимальной ширины. См. скриншот ниже.

Также, мы можем контролировать качество и соответственно вес изображений при помощи настройки “Степень сжатия изображений”. Программа автоматически может сжимать картинки, тем самым, делая их легче по размеру, если это необходимо. См. скриншот ниже.

Чем меньше мы укажем значение в данном параметре, тем качественнее и больше по размеру будут картинки. чем выше мы увеличим степень сжатия, тем легче и менее качественнее изображения мы получим на выходе.
Итак, “Количество изображений” минимум и максимум. Мы можем задать, какое количество изображений хотим видеть в наших статьях. Можно контролировать как минимальное значение, сколько картинок добавится в статью, так и максимальное. См. скриншот ниже.

Теперь поговорим про функцию вставки видео. Для включения выбираем “Парсить из Youtube”. Программа будет находить видеоролики на основании подаваемых ключевых данных и размещать их в статьях. См. скриншот ниже.

Также, в крайне редких случаях, если вдруг, в нашей статье вставляется видео не совсем соответствующее исходным данным, мы можем уточнить запрос задав “Дополнение к запросам”. Данное расширение, на основании “Дополнения”, позволит более точно произвести поиск и подбор ролика в ситуации, когда это действительно необходимо. См. скриншот ниже.

Также мы можем задать требуемое количество видеороликов, которые будут вставляться в конце статьи, откорректировав минимальное и максимальное значения. См. скриншот ниже.

Итак, кратко резюмируя базовую информацию, если мы хотим видеть в наших статьях сгенерированные картинки, используем режимы Dall-e 2 и Dall-e 3 и покупаем аккаунт ChatGPT с АПИ.
Если хотим, чтобы в наших статьях были картинки из поисковой выдачи, выбираем парсить из выдачи Google и Bing.
Если планируем генерировать большие объемы статей с картинками выбираем парсинг из XMLStock и регистрируем аккаунт на их сайте.
Если хотим картинки из фотобанков, выбираем Freepik, Pexels и Pixabay.
Хотим брать картинки как у сайтов конкурентов, предварительно спарсив их статьи, выбираем режим “Парсить из доноров”.
Хотим вставлять в статьи заранее подготовленные картинки, выбираем вставлять “Случайные из папки” и даем программе эту папку.
Видео-инструкция:
